Explique-moi internet
Paul Baran est considéré comme un des acteurs principaux de la création d'Internet. Il eu l'idée, en 1964, de créer un réseau sous forme de grande toile. Il avait réalisé qu'un système centralisé était vulnérable car la destruction de son noyau provoquait l'anéantissement des communications. Il mit donc au point un réseau hybride d'architectures étoilées et maillées dans lequel les données se déplaceraient de façon dynamique, en « cherchant » le chemin le moins encombré, et en « patientant » si toutes les routes étaient encombrées.

Le web n'est pas internet
Pour expliquer la différence entre web et Internet, on pourrait dire que le web n'est pas l'Internet mais sa principale application. Il s'agit d'un système de publication et de consultation de documents : des sons, des images et des textes comme l'article que vous êtes en train de lire... Ce système utilise les techniques de l'hypertexte, c'est-à-dire des hyperliens ou liens qui vous permettent de surfer d'une partie d'un document à une autre ou d'un document à un autre d'un simple clic.
Internet (contraction de Inter Network) est un réseau informatique qui relie des ordinateurs entre eux à l'échelle du monde. Ce gigantesque réseau se compose de millions de réseaux publics et privés plus petits, par exemple des réseaux universitaires, gouvernementaux ou commerciaux. Cette vaste infrastructure informatique repose sur le protocole de communication IP (pour Internet Protocol), qui permet d'acheminer des données entre les ordinateurs via un maillage de serveurs et de routeurs.
Pour expliquer la différence entre web et Internet, on pourrait dire que le web n'est pas l'Internet mais sa principale application. Il s'agit d'un système de publication et de consultation de documents : des sons, des images et des textes comme l'article que vous êtes en train de lire... Ce système utilise les techniques de l'hypertexte, c'est-à-dire des hyperliens ou liens qui vous permettent de surfer d'une partie d'un document à une autre ou d'un document à un autre d'un simple clic.
Internet (contraction de Inter Network) est un réseau informatique qui relie des ordinateurs entre eux à l'échelle du monde. Ce gigantesque réseau se compose de millions de réseaux publics et privés plus petits, par exemple des réseaux universitaires, gouvernementaux ou commerciaux. Cette vaste infrastructure informatique repose sur le protocole de communication IP (pour Internet Protocol), qui permet d'acheminer des données entre les ordinateurs via un maillage de serveurs et de routeurs.
Avant de poursuivre une petite vidéo qui pose le contexte général
Et maintenant moi : créateur d'un site web !
La plupart des sites internet actuels fonctionnent avec une base de données.Celle-ci stocke le contenu (textes, fichiers, liens...) et à côté de celle-ci se trouve un fichier de "mise en forme" que le nomme CSS.
Lorsque le site web est appelé, une partie du contenu de la base de données est affiché (par exemple la page d'accueil) et la mise en forme lui est appliquée juste avant son affichage sur votre écran.
Ce découplage entre contenu et forme offre pas mal de souplesse et notamment la possibilité de pouvoir, en changeant JUSTE un fichier (le CSS), de donner un autre look à l'ensemble du site web !
Le rassemblement du contenu complet du site web sous forme de base de données permet aussi certains usages pratiques, entre autre la génération d'un flux RSS (à chaque modification de la base de données, une onde est envoyée sur le net avec les infos de ce qui a changé).
Super ! mais du coup pour fonctionner votre site web demande que votre hébergeur offre quelques fonctions précises : la principale étant d'avoir une base de données ;-)
A savoir avant de penser installer un tel site web ;-)
Quelques définitions
- un hébergement est un espace, sorte de disque dur, que vous louez auprès d'un hébergeur (ovh, free, haisoft, gandi...). Cet espace vous permet d'y déposer des fichiers de tout type (doc, pdf, images, vidéos, texte, html...). Voyez le vraiment comme un disque dur virtuel (un cloud). Cet espace possède une adresse pas très pratique, ni parlante, il s'agit le plus souvent d'un truc ressemblant à un adresse IP ou à un nom étrange
- ce nom ou adresse ne vous permet pas de voir le contenu de votre disque dur virtuel à travers un navigateur !
- ce sera par contre l'adresse que vous utiliserez dans votre logiciel FTP
- un hébergement coûte entre 25 et .... euros /an en fonction des options (taille du disque dur, nombre de base de données, vitesse, backup...)
- un logiciel FTP est un outil qui crée un "tunnel" entre votre ordinateur et le disque dur virtuel chez votre hébergeur. Il va vous permettre de faire passer des fichiers de votre pc vers le serveur ou inversement. Pour le faire fonctionner, vous recevez de votre hébergeur les infos utiles ( le nom du serveur / votre nom d'utilisateur / un mot de passe d'accès )
- il existe plusieurs logiciels dont certains opensource et gratuits : le plus connu est filezilla : https://filezilla-project.org
- un nom de domaine est une "surcouche" plus compréhensible par des humains que l'on vient placer sur votre hébergement (ou une partie de celui-ci). Il s'agit par exemple de cooptic.be. Ce nom de domaine prend la place de l'adresse étrange de votre serveur. Il est parfaitement possible d'avoir plusieurs noms de domaines pour un seul hébergement.
- cooptic.be, cooptic.org et cooptic.net pointent vers le même serveur
- ou cooptic.net pointe vers telle partie du serveur alors que coop-site.net pointe vers telle autre partie de ce même serveur
- un nom de domaine se loue chez la plupart des hébergeurs (entre 5 et 20 euros/an). Il est géré dans chaque pays par un organisme => https://www.dnsbelgium.be/fr
- une base de données (db) est un service que l'on peut louer (le plus souvent c'est inclus d'office) avec son hébergement. La base de données peut accueillir des tables dans lesquelles on retrouve des données (une table = un tableur, une donnée = une ligne dans ce tableur). Votre hébergeur vous fournira le nom de nom du serveur de la db, le nom de la db, un utilisateur et un mot de passe).
- le html est le language de base pour créer une page d'un site web. De nos jours, la plupart des sites web facilitent les choses et évitent aux utilisateurs de devoir utiliser ce html. Dans yeswiki, vous n'écrivez pas du html ;-) => si vous voulez voir du html faites clic droit et voir le code source de la page !
Bon et pour faire tourner un yeswiki
il vous faudra :- un hébergement proposant une base de données (en général l'offre de base des hébergements suffit pour débuter et offre une db)
- un logiciel ftp pour déposer le yeswiki sur votre hébergement (et don cles infos de connexion reçues de votre hébergeur)
- un nom de domaine pour avoir accès à votre site web (en général on loue un pack "hébergement et nom de domaine")
- les infos relatives à votre db (que vous devrez donner à yeswiki lors de son installation et reçues de votre hébergeur)
Déposer mon wiki sur mon hébergement avec Filezilla
créer mon yeswiki
Ci-dessous, un texte en provenance de la rtbf / une autre façon de présenter le web
L’odyssée des données
Une des particularités du monde numérique est qu’il n’a pas, ou peu, de frontières. Nos données traversent souvent des milliers, voire des dizaines de milliers de kilomètres, depuis le lieu où elles sont stockées, jusqu’au terminal où elles seront traitées pour fournir le service ou le contenu désiré.Pour mieux comprendre l’infrastructure qui soutient internet, imaginons que l’univers du numérique soit en fait une sorte d’arbre : ses racines sont les serveurs de stockage, son feuillage peut s’apparenter aux internautes. Entre les deux, via le tronc et les branches, coule la sève, dans les deux sens, transportant les data : c’est le réseau télécom.
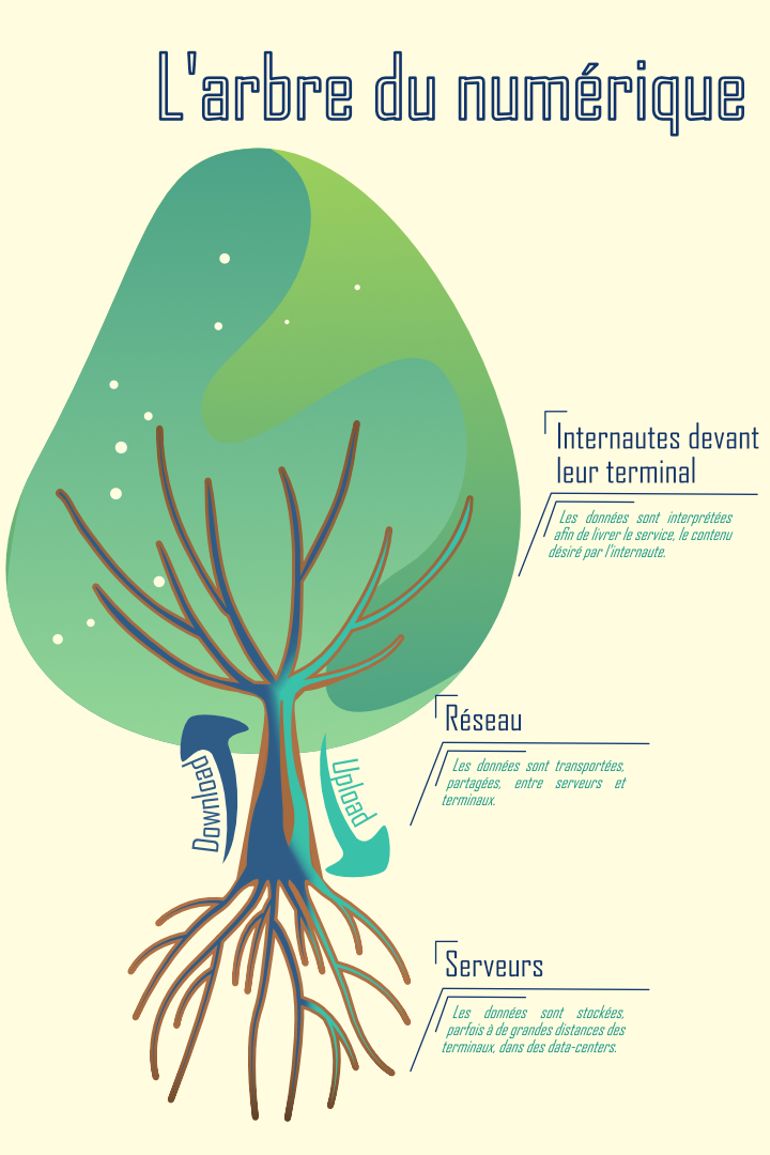
L'arbre du numérique - © A. Lo., selon un graphisme de Freepik, du site FlatIcons
Dans cet organisme numérique, on distingue donc trois stades :
- Nos racines sont les serveurs, où sont hébergées les plateformes et stockées les données. Une grande majorité d’entre eux sont dans des data centers.
- Tronc et branches sont le réseau télécom où transitent les données, qui est souvent divisé en trois parties :
- le tronc de l’arbre est le “noyau”, représentant ce que l’on appelle les autoroutes du web, ces câbles sous-marins de fibre optique où transitent plus de 90% des données
- Les branches principales représentent le réseau reliant les plus gros clients consommateurs et producteurs de données. En jargon, ce stade est nommé “métro”.
- Enfin, les plus petites branches, qui portent les feuilles, sont “l’accès local”, les derniers kilomètres du réseau pour atteindre chaque utilisateur d’internet, dans son foyer.
- Enfin, le feuillage représente les terminaux, qui vont recevoir les données et les interpréter afin de délivrer le service demandé par l’internaute. Une grande variété d’appareils entrent dans cette catégorie, les plus utilisés étant les ordinateurs, smartphones, TV’s, consoles et plus récemment, les objets connectés.
Tout comme dans un arbre, où les flux de sève entre racines et feuilles vont dans les deux sens, les flux de données sont en fait des échanges permanents entre serveurs et terminaux. Le flux le plus important est le download, lorsqu’un internaute charge un contenu depuis un serveur distant, et dans l’autre sens, il y a l’upload, quand l’utilisateur envoie des données vers les serveurs pour faire une requête, ou pour stocker du contenu, ou que le serveur demande des données pour livrer le service demandé.